
สุดยอดเครื่องมือขุดข้อมูลฟรี 19 รายการ
มีการกล่าวอย่างถูกต้องว่าข้อมูลคือเงินในโลกปัจจุบัน นอกจากการเปลี่ยนผ่านสู่โลกที่อิงแอพแล้ว ข้อมูลก็เติบโตขึ้นแบบทวีคูณ อย่างไรก็ตาม ข้อมูลส่วนใหญ่ไม่มีโครงสร้าง จึงต้องใช้กระบวนการและวิธีการดึงข้อมูลที่เป็นประโยชน์ออกจากข้อมูลและแปลงเป็นรูปแบบที่เข้าใจและใช้งานได้
การขุดข้อมูลหรือ Knowledge Discovery in Databases เป็นกระบวนการในการค้นหารูปแบบในชุดข้อมูลขนาดใหญ่ด้วยปัญญาประดิษฐ์ การเรียนรู้ของเครื่อง สถิติ และระบบฐานข้อมูล
เครื่องมือขุดข้อมูลฟรีมีตั้งแต่สภาพแวดล้อมการพัฒนาแบบจำลองที่สมบูรณ์ เช่น Knime และ Orange ไปจนถึงไลบรารีที่หลากหลายที่เขียนด้วยภาษา Java, C++ และส่วนใหญ่มักเป็นในภาษา Python งานสี่ประเภทที่ปกติแล้วเกี่ยวข้องกับการทำเหมืองข้อมูล:
การจัดประเภท: งานของการสรุปโครงสร้างที่คุ้นเคยเพื่อใช้กับข้อมูลใหม่ Clustering: งานค้นหากลุ่มและโครงสร้างในข้อมูลที่ไม่ทางใดก็ทางหนึ่ง โดยไม่ต้องใช้โครงสร้างที่บันทึกไว้ในข้อมูล การเรียนรู้กฎการเชื่อมโยง: ค้นหาความสัมพันธ์ระหว่างตัวแปร การถดถอย: มีวัตถุประสงค์เพื่อค้นหาฟังก์ชันที่จำลองข้อมูลโดยมีข้อผิดพลาดน้อยที่สุด
รายการเครื่องมือซอฟต์แวร์ฟรีสำหรับการทำเหมืองข้อมูลด้านล่าง –
รายชื่อเครื่องมือขุดข้อมูลฟรีที่ดีที่สุดในปี 2018:-
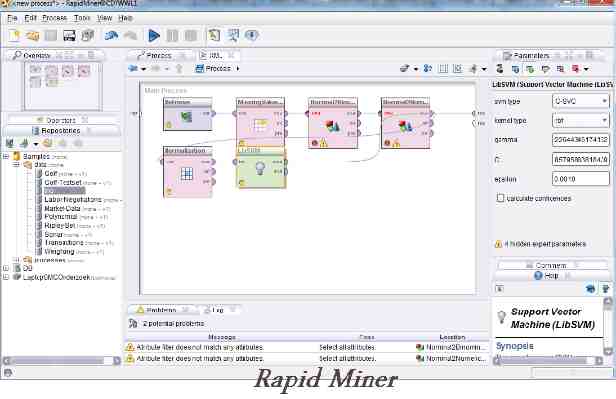
1. Rapid Miner –
Rapid Miner เดิมเรียกว่า YALE (เป็นอีกสภาพแวดล้อมการเรียนรู้) เป็นสภาพแวดล้อมสำหรับการเรียนรู้ของเครื่องและการทดลองทำเหมืองข้อมูลที่ใช้สำหรับการวิจัยและงานเหมืองข้อมูลในโลกแห่งความเป็นจริง ไม่ต้องสงสัยเลยว่าระบบโอเพ่นซอร์สชั้นนำของโลกสำหรับการทำเหมืองข้อมูล เครื่องมือนี้เขียนด้วยภาษาการเขียนโปรแกรม Java ซึ่งนำเสนอการวิเคราะห์ขั้นสูงผ่านเฟรมเวิร์กที่ใช้เทมเพลต
ช่วยให้การทดลองประกอบด้วยโอเปอเรเตอร์ที่สามารถซ้อนได้ตามอำเภอใจจำนวนมาก ซึ่งมีรายละเอียดอยู่ในไฟล์ XML และสร้างด้วยอินเทอร์เฟซผู้ใช้แบบกราฟิกของ Rapid Miner สิ่งที่ดีที่สุดคือผู้ใช้ไม่จำเป็นต้องเขียนโค้ด มีเทมเพลตและเครื่องมืออื่นๆ มากมายที่ช่วยให้เราวิเคราะห์ข้อมูลได้อย่างง่ายดาย
See Also: An Insight into 26 Big Data Analytic Techniques: Part 1
2. IBM SPSS Modeler –
เวิร์กเบนช์เครื่องมือ IBM SPSS Modeler เหมาะที่สุดสำหรับการทำงานในโปรเจ็กต์ขนาดใหญ่ เช่น การวิเคราะห์ข้อความ และอินเทอร์เฟซแบบภาพนั้นมีค่าอย่างยิ่ง ช่วยให้คุณสร้างอัลกอริธึมการขุดข้อมูลที่หลากหลายโดยไม่ต้องเขียนโปรแกรม นอกจากนี้ยังสามารถใช้สำหรับการตรวจจับความผิดปกติ, เครือข่ายเบย์เซียน, CARMA, การถดถอยค็อกซ์ และเครือข่ายประสาทเทียมพื้นฐานที่ใช้เพอร์เซปตรอนหลายชั้นพร้อมการเรียนรู้การแพร่กระจายกลับ ไม่เหมาะสำหรับคนใจอ่อน
3. Oracle Data Mining –
ผู้ตีรายใหญ่อีกรายในขอบเขตการทำเหมืองข้อมูลคือ Oracle การทำเหมืองข้อมูล Oracle เป็นส่วนหนึ่งของตัวเลือกฐานข้อมูลการวิเคราะห์ขั้นสูง ช่วยให้ผู้ใช้ค้นพบข้อมูลเชิงลึก คาดการณ์ และใช้ประโยชน์จากข้อมูล Oracle ของตนได้ คุณสามารถสร้างแบบจำลองเพื่อค้นหาพฤติกรรมของลูกค้าที่กำหนดเป้าหมายลูกค้าที่ดีที่สุดและพัฒนาโปรไฟล์
Oracle Data Miner GUI ช่วยให้นักวิเคราะห์ข้อมูล นักวิเคราะห์ธุรกิจ และนักวิทยาศาสตร์ข้อมูลสามารถทำงานกับข้อมูลภายในฐานข้อมูลโดยใช้โซลูชันการลากและวางที่ค่อนข้างสวยงาม นอกจากนี้ยังสามารถสร้างสคริปต์ SQL และ PL/SQL สำหรับการทำงานอัตโนมัติ การตั้งเวลา และการปรับใช้ทั่วทั้งองค์กร
4. เทราดาต้า –
Teradata ตระหนักดีว่าแม้ว่าข้อมูลขนาดใหญ่จะยอดเยี่ยม แต่ถ้าคุณไม่รู้วิธีวิเคราะห์และใช้งานจริง ๆ มันก็ไร้ค่า ลองนึกภาพว่ามีจุดข้อมูลหลายล้านจุดโดยไม่มีทักษะในการค้นหา นั่นคือสิ่งที่ Teradata เข้ามา พวกเขาให้บริการโซลูชั่นแบบ end-to-end และบริการในคลังข้อมูล บิ๊กดาต้า และการวิเคราะห์ และแอปพลิเคชันการตลาด
นอกจากนี้ Teradata ยังนำเสนอบริการที่หลากหลาย รวมถึงการนำไปปฏิบัติ การให้คำปรึกษาทางธุรกิจ การฝึกอบรม และการสนับสนุน
ดูเพิ่มเติมที่: 36 ข้อเท็จจริงที่น่าสนใจเกี่ยวกับคลาวด์คอมพิวติ้ง
5. ข้อมูลในกรอบ –
เป็นโซลูชันที่มีการจัดการเต็มรูปแบบ ซึ่งหมายความว่าคุณไม่จำเป็นต้องดำเนินการใดๆ นอกจากนั่งรอข้อมูลเชิงลึก Framed Data นำข้อมูลจากธุรกิจมาเปลี่ยนเป็นข้อมูลเชิงลึกและการตัดสินใจที่นำไปใช้ได้จริง พวกเขาฝึกอบรม เพิ่มประสิทธิภาพ และจัดเก็บโมเดลผลิตภัณฑ์ไอออนไนซ์ในคลาวด์ของตน และจัดเตรียมการคาดการณ์ผ่าน API ขจัดโอเวอร์เฮดของโครงสร้างพื้นฐาน พวกเขามีแดชบอร์ดและเครื่องมือวิเคราะห์สถานการณ์ที่บอกคุณว่าคันโยกของบริษัทใดที่ขับเคลื่อนเมตริกที่คุณสนใจ
6. คางคก –
Kaggle เป็นชุมชนวิทยาศาสตร์ข้อมูลที่ใหญ่ที่สุดในโลก บริษัทและนักวิจัยโพสต์ข้อมูล นักสถิติ และผู้ขุดข้อมูลจากทั่วทุกมุมโลกแข่งขันกันเพื่อผลิตแบบจำลองที่ดีที่สุด
Kaggle เป็นแพลตฟอร์มสำหรับการแข่งขันด้านวิทยาศาสตร์ข้อมูล ช่วยคุณแก้ปัญหาที่ยาก รับสมัครทีมที่เข้มแข็ง และเพิ่มพลังความสามารถด้านวิทยาศาสตร์ข้อมูลของคุณ
3 ขั้นตอนการทำงาน –
อัปโหลดปัญหาการทำนาย ส่ง ประเมินและแลกเปลี่ยน
7. วีก้า –
WEKA เป็นเครื่องมือขุดข้อมูลที่ดีที่สุดที่ซับซ้อนมาก มันแสดงความสัมพันธ์ที่หลากหลายระหว่างชุดข้อมูล คลัสเตอร์ การสร้างแบบจำลองเชิงคาดการณ์ การแสดงภาพ ฯลฯ มีตัวแยกประเภทจำนวนหนึ่งที่คุณสามารถนำไปใช้เพื่อรับข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับข้อมูล
8. สั่น –
Rattle ย่อมาจาก R Analytical Tool เพื่อเรียนรู้อย่างง่ายดาย นำเสนอข้อมูลสรุปทางสถิติและภาพ แปลงข้อมูลเป็นรูปแบบที่สามารถสร้างแบบจำลองได้ง่าย สร้างแบบจำลองทั้งที่ไม่ได้รับการดูแลและอยู่ภายใต้การดูแลจากข้อมูล นำเสนอประสิทธิภาพของแบบจำลองแบบกราฟิก และให้คะแนนชุดข้อมูลใหม่
เป็นชุดเครื่องมือขุดข้อมูลที่ดีที่สุดฟรีและโอเพ่นซอร์สที่เขียนด้วยภาษาสถิติ R โดยใช้อินเทอร์เฟซกราฟิก Gnome มันทำงานภายใต้ GNU/Linux, Macintosh OS X และ MS/Windows
9. KNIME –
Konstanz Information Miner เป็นแพลตฟอร์มการรวมข้อมูล การประมวลผล การวิเคราะห์และการสำรวจโอเพนซอร์สที่เป็นมิตรต่อผู้ใช้ มีอินเทอร์เฟซผู้ใช้แบบกราฟิกซึ่งช่วยให้ผู้ใช้สามารถเชื่อมต่อโหนดสำหรับการประมวลผลข้อมูลได้อย่างง่ายดาย
KNIME ยังรวมส่วนประกอบต่างๆ สำหรับการเรียนรู้ของเครื่องและการทำเหมืองข้อมูลผ่านแนวคิดการวางท่อข้อมูลแบบแยกส่วน และได้รับความสนใจจากระบบธุรกิจอัจฉริยะและการวิเคราะห์ข้อมูลทางการเงิน
10. หลาม –
ในฐานะที่เป็นภาษาโอเพ่นซอร์สฟรี Python มักถูกนำมาเปรียบเทียบกับ R เพื่อความสะดวกในการใช้งาน ต่างจาก R ตรงที่เส้นโค้งการเรียนรู้ของ Python นั้นสั้นมากจนกลายเป็นตำนาน ผู้ใช้หลายคนพบว่าพวกเขาสามารถเริ่มสร้างชุดข้อมูลและทำการวิเคราะห์ความสัมพันธ์ที่ซับซ้อนอย่างยิ่งได้ในเวลาไม่กี่นาที การแสดงภาพข้อมูลกรณีการใช้งานทางธุรกิจโดยทั่วไปจะตรงไปตรงมา ตราบใดที่คุณคุ้นเคยกับแนวคิดการเขียนโปรแกรมพื้นฐาน เช่น ตัวแปร ประเภทข้อมูล ฟังก์ชัน เงื่อนไข และลูป
11. ส้ม –
Orange เป็นชุดซอฟต์แวร์การทำเหมืองข้อมูลและการเรียนรู้ของเครื่องที่เขียนด้วยภาษา Python เป็นการสร้างภาพข้อมูลและการวิเคราะห์แบบโอเพ่นซอร์สสำหรับมือใหม่และผู้เชี่ยวชาญ การขุดข้อมูลสามารถทำได้ผ่านการเขียนโปรแกรมด้วยภาพหรือการเขียนสคริปต์ Python นอกจากนี้ยังอัดแน่นไปด้วยคุณสมบัติสำหรับการวิเคราะห์ข้อมูล การแสดงภาพแบบต่างๆ ตั้งแต่ scatterplots แผนภูมิแท่ง ต้นไม้ ไปจนถึง dendrograms เครือข่าย และแผนที่ความร้อน
ดูเพิ่มเติม: เครื่องมือทำความสะอาดข้อมูลออฟไลน์ที่ดีที่สุด
12. การทำเหมืองข้อมูล SAS –
ค้นพบรูปแบบชุดข้อมูลโดยใช้ซอฟต์แวร์เชิงพาณิชย์ SAS Data Mining การสร้างแบบจำลองเชิงพรรณนาและการทำนายจะให้ข้อมูลเชิงลึกเพื่อความเข้าใจในข้อมูลที่ดีขึ้น พวกเขามี GUI ที่ใช้งานง่าย พวกเขามีเครื่องมืออัตโนมัติตั้งแต่การประมวลผลข้อมูล การจัดกลุ่มไปจนถึงจุดสิ้นสุด ซึ่งคุณจะพบผลลัพธ์ที่ดีที่สุดสำหรับการตัดสินใจที่ถูกต้อง การเป็นซอฟต์แวร์เชิงพาณิชย์ยังรวมถึงเครื่องมือขั้นสูง เช่น การประมวลผลที่ปรับขนาดได้ การทำงานอัตโนมัติ อัลกอริธึมแบบเข้มข้น การสร้างแบบจำลอง การสร้างภาพข้อมูล และการสำรวจ เป็นต้น
13. อาปาเช่ ควาญ –
Apache Mahout เป็นโครงการของ Apache Software Foundation เพื่อสร้างการติดตั้งใช้งานฟรีของอัลกอริธึมการเรียนรู้ของเครื่องแบบกระจายหรือแบบปรับขนาดได้ โดยมุ่งเน้นที่การกรองร่วมกัน การจัดกลุ่ม และการจัดประเภทเป็นหลัก
Apache Mahout สนับสนุนกรณีการใช้งานหลักสามกรณี: การขุดคำแนะนำใช้พฤติกรรมของผู้ใช้และพยายามค้นหารายการที่ผู้ใช้อาจชอบ การทำคลัสเตอร์ใช้เช่นเอกสารข้อความและจัดกลุ่มเป็นกลุ่มของเอกสารที่เกี่ยวข้อง การจัดประเภทเรียนรู้จากเอกสารที่จัดประเภทที่มีอยู่ว่าเอกสารของประเภทใดมีลักษณะอย่างไรและสามารถกำหนดเอกสารที่ไม่มีป้ายกำกับให้กับประเภทที่ถูกต้อง (หวังว่า)
14. พีเอสพีพี –
PSPP เป็นโปรแกรมสำหรับวิเคราะห์สถิติของข้อมูลตัวอย่าง มีอินเทอร์เฟซผู้ใช้แบบกราฟิกและอินเทอร์เฟซบรรทัดคำสั่งทั่วไป มันเขียนด้วยภาษา C ใช้ GNU Scientific Library สำหรับกิจวัตรทางคณิตศาสตร์และพล็อต UTILS เพื่อสร้างกราฟ เป็นการทดแทนฟรีสำหรับโปรแกรม SPSS ที่เป็นกรรมสิทธิ์ (จาก IBM) คาดการณ์ด้วยความมั่นใจว่าจะเกิดอะไรขึ้นต่อไป เพื่อให้คุณตัดสินใจได้อย่างชาญฉลาดยิ่งขึ้น แก้ปัญหาและปรับปรุงผลลัพธ์
ดูเพิ่มเติม: เครื่องมือจัดเก็บข้อมูลบนคลาวด์ 11 อันดับแรกสำหรับ Big Data
15. jHepWork –
jHepWork เป็นเฟรมเวิร์กการวิเคราะห์ข้อมูลแบบโอเพ่นซอร์สฟรีที่สร้างขึ้นโดยพยายามสร้างสภาพแวดล้อมการวิเคราะห์ข้อมูลโดยใช้แพ็คเกจโอเพ่นซอร์สพร้อมอินเทอร์เฟซผู้ใช้ที่เข้าใจได้ และเพื่อสร้างเครื่องมือที่สามารถแข่งขันกับโปรแกรมเชิงพาณิชย์ได้
JHepWork แสดงแผนภาพ 2D และ 3D แบบโต้ตอบสำหรับชุดข้อมูลเพื่อการวิเคราะห์ที่ดียิ่งขึ้น มีห้องสมุดวิทยาศาสตร์เชิงตัวเลขและฟังก์ชันทางคณิตศาสตร์ที่นำมาใช้ใน Java jHepWork อิงจากภาษาการเขียนโปรแกรมระดับสูงของ Jython แต่การเข้ารหัส Java ยังสามารถใช้เพื่อเรียกไลบรารีตัวเลขและกราฟิกของ jHepWork ได้อีกด้วย
16. ภาษาการเขียนโปรแกรม R–
ไม่ต้องสงสัยเลยว่าทำไม R จึงเป็นซุปเปอร์สตาร์ของเครื่องมือขุดข้อมูลฟรีในรายการนี้ เป็นโอเพ่นซอร์สฟรีและง่ายต่อการใช้งานสำหรับผู้ที่มีประสบการณ์การเขียนโปรแกรมเพียงเล็กน้อยหรือไม่มีเลย มีห้องสมุดหลายพันแห่งที่สามารถรวมเข้ากับสภาพแวดล้อม R ได้ ทำให้เป็นสภาพแวดล้อมการทำเหมืองข้อมูลที่มีประสิทธิภาพ เป็นภาษาการเขียนโปรแกรมซอฟต์แวร์ฟรีและสภาพแวดล้อมของซอฟต์แวร์สำหรับการคำนวณทางสถิติและกราฟิก
ภาษา R ใช้กันอย่างแพร่หลายในหมู่ผู้ทำเหมืองข้อมูลเพื่อพัฒนาซอฟต์แวร์ทางสถิติและการวิเคราะห์ข้อมูล ใช้งานง่ายและขยายได้เพิ่มความนิยมของ R อย่างมากในช่วงไม่กี่ปีที่ผ่านมา
17. เพนทาโฮ –
Pentaho มีแพลตฟอร์มที่ครอบคลุมสำหรับการบูรณาการข้อมูล การวิเคราะห์ธุรกิจ และบิ๊กดาต้า ด้วยเครื่องมือเชิงพาณิชย์นี้ คุณสามารถผสมผสานข้อมูลจากแหล่งใดก็ได้ รับข้อมูลเชิงลึกเกี่ยวกับข้อมูลธุรกิจของคุณ และทำการตัดสินใจที่ขับเคลื่อนด้วยข้อมูลที่แม่นยำยิ่งขึ้นสำหรับอนาคต
คุณอาจชอบ: เครื่องมือดึงข้อมูลโอเพ่นซอร์ส 10 อันดับแรกของ Big Data
18. ทานากรา –
TANAGRA เป็นซอฟต์แวร์ขุดข้อมูลเพื่อวัตถุประสงค์ทางวิชาการและการวิจัย มีเครื่องมือสำหรับการวิเคราะห์ข้อมูลเชิงสำรวจ การเรียนรู้ทางสถิติ การเรียนรู้ของเครื่องและฐานข้อมูล Tanagra มีการเรียนรู้ภายใต้การดูแลบางส่วน แต่ยังรวมถึงกระบวนทัศน์อื่นๆ เช่น การจัดกลุ่ม การวิเคราะห์แฟกทอเรียล สถิติเชิงพาราเมตริกและแบบไม่อิงพารามิเตอร์ กฎการเชื่อมโยง การเลือกคุณลักษณะ และอัลกอริธึมการสร้าง
19. เอ็นแอลทีเค –
Natural Language Toolkit เป็นชุดของไลบรารีและโปรแกรมสำหรับการประมวลผลภาษาธรรมชาติเชิงสัญลักษณ์และทางสถิติ (NLP) สำหรับภาษาไพ ธ อน มีกลุ่มเครื่องมือประมวลผลภาษา เช่น การทำเหมืองข้อมูล การเรียนรู้ของเครื่อง การแยกข้อมูล การวิเคราะห์ความรู้สึก และงานการประมวลผลภาษาอื่นๆ สร้างโปรแกรมหลามเพื่อจัดการกับข้อมูลภาษามนุษย์
เราหวังว่ารายการเครื่องมือขุดข้อมูลฟรีที่ดีที่สุดของเราจะช่วยคุณได้ เราอยากทราบความคิดเห็นของคุณ โปรดแบ่งปันความคิดเห็นของคุณในส่วนความคิดเห็นด้านล่าง
การทำเหมืองข้อมูล
ปัจจุบันการเขียนโปรแกรมคอมพิวเตอร์ เพื่อพัฒนาโปรแกรมระบบงานด้านธุรกิจขึ้นมาใช้งาน อำนวยความสะดวกในเรื่องของการคำนวณ ประมวลผล เก็บรวบรวมข่าวสาร ค้นหา และออกรายงานได้อย่างรวดเร็ว ด้วยความสามารถของคอมพิวเตอร์นั้น ถือเป็นเรื่องปกติพื้นฐานไปเสียแล้วสำหรับการพัฒนาระบบงานในปัจจุบัน
ถ้าหาก programmer หรือผู้ที่มีส่วนเกี่ยวข้องในการพัฒนาโปรแกรมระบบงานด้านธุรกิจ ไม่มีการพัฒนาแนวคิดใหม่ ๆ ที่จะนำเทคนิควิธี หรือ Algorithm มาใช้กับข้อมูล ในขณะที่มีอุปกรณ์และเครื่องมือสมัยใหม่ต่าง ๆ ที่เอื้อประโยชน์ในการพัฒนา ความสามารถของเครื่องคอมพิวเตอร์ก็วิวัฒนาการอย่างรวดเร็ว มีประสิทธิภาพสูง ความจุมหาศาล แต่ถ้าเราไม่สามารถที่จะใช้สิ่งที่มีอยู่ได้อย่างเต็มประสิทธิภาพและคุ้มค่า ย่อมจะส่งผลต่อระบบงานที่ล้าหลัง ล้าสมัย ขาดการวิเคราะห์และสกัดข้อมูลที่ซ่อนเร้นอยู่ในฐานข้อมูลนั้นขึ้นมาใช้ประโยชน์อย่างที่ควรจะเป็น และนั่นก็บ่งบกถึงประสิทธิภาพของบุคคลที่ขาดความคิดสร้างสรรค์ ขาดความสามารถ องค์กรของเราก็จะล้าหลังในธุรกิจ ตามคู่แข่งไม่ทัน ขาดข้อมูลข่าวสารที่จะนำไปสร้างกลยุทธ์ และสร้างความได้เปรียบให้กับองค์กร และมันอาจจะนำมาซึ่งอนาคตขององค์กร ว่าจะสามารถคงอยู่ได้หรือไม่ กับสภาวการณ์การแข่งขันด้านธุรกิจในปัจจุบันที่มีความรุนแรง
ดังนั้นเราควรทำความรู้จักกับ การแสวงหาความรู้ใหม่ด้วยเทคนิคของการการทำเหมืองข้อมูล
Data Mining คือ การค้นหาความสัมพันธ์และรูปแบบ(Pattern) ทั้งหมด ซึ่งมีอยู่จริงในฐานข้อมูล แต่ได้ถูกซ่อนไว้ภายในข้อมูลจำนวนมาก Data Mining จะทำการสำรวจและวิเคราะห์อย่างอัตโนมัติหรือกึ่งอัตโนมัติ ในปริมาณข้อมูลจำนวนมากให้อยู่ในรูปแบบที่เต็มไปด้วยความหมายและอยู่ในรูปของกฎ (Rule) โดยความสัมพันธ์เหล่านี้แสดงให้เห็นถึงความรู้ต่าง ๆ ที่มีประโยชน์ในฐานข้อมูล
Data Mining จะเป็นการสังเคราะห์ข้อมูลอย่างละเอียดจากฐานข้อมูลขนาดใหญ่ หรืออาจวิเคราะห์มาจากรายการ Transaction โดยเรียนรู้ข้อมูลจากอดีต หรือปัจจุบันผลลัพธ์ที่ได้จากการสังเคราะห์ของ Data Mining อาจจะเป็นข้อมูลแบบ Unknow , Valid, หรือ Actionable ซึ่งความหมายของข้อมูลทั้ง 3 ประเภทนี้ มีดังนี้
1. ข้อมูลแบบ Unknow เป็นข้อมูลที่ผู้ใช้งานไม่เคยรู้มาก่อน ไม่ชัดเจน ไม่สามารถตั้งสมมติฐานล่วงหน้าว่าจะเป็นแบบใด เช่น
Ex : ห้างสรรสินค้าแห่งหนึ่งค้นพบพฤติกรรมของผู้บริโภค ที่พ่อบ้านมักซื้อเบียร์และผ้าอ้อมในวันศุกร์ตอนเย็น ดังนั้นเป็นสัญญาณให้เจ้าของกิจการควรจะเตรียมสินค้าไว้เพื่อจำหน่าย ในขณะที่ห้างคู่แข่งอาจจะไม่รู้ข้อมูลเหล่านี้
Ex: เจ้าของร้านขายรถยนต์พบว่ารถยนต์ขนาดใหญ่ ราคาแพงมักจะถูกซื้อโดยคนที่สูงอายุ ซึ่งเจ้าของร้านไม่เคยรู้มาก่อน แต่ข้อมูลดังกล่าวไม่เป็นลักษณะของ Unknow เพราะสมมติฐานดังกล่าวมีอยู่ คือ คนที่มีอายุมักมีฐานะดีขึ้น เมื่อเทียบกับคนในวัยที่อายุน้อย
2. ข้อมูลแบบ Valid เมื่อผู้ใช้เริ่มใช้เทคนิคของ Data Mining จะค้นพบสิ่งที่น่าสนใจตลอดเวลา แต่จะต้องพิจารณาด้วยว่าสิ่งนั้นถูกต้อง (Valid) หรือไม่ เช่น มักจะพบว่ามีความสัมพันธ์ของการซื้อสินค้า 2 อย่างเสมอ เมื่อจำนวนความหลากหลายของสินค้ามากขึ้น แต่ไม่ได้หมายความว่าจะต้องให้ห้างสรรพสินค้า เก็บสินค้าในคลังมากขึ้น เพราะข้อมูลที่ได้อาจเกิดความคลาดเคลื่อน เพราะฉะนั้นจะต้องทำการตรวจสอบความถูกต้อง (Validation and Checking) ของข้อมูลและวิเคราะห์ความถูกต้องอีกครั้ง
3. ข้อมูลแบบ Actionable : ข้อมูลจะต้องถูกแปลงออกมาและนำมาตัดสินใจ เพื่อสร้างความได้เปรียบในเชิงธุรกิจ บางครั้งข้อมูลที่เราค้นพบเป็นสิ่งที่คู่แข่งได้ทำไปเสียแล้ว (เราช้าไป) หรืออาจผิดกฎหมาย ซึ่งจะต้องมีวิจารณญาณในการใช้ด้วย บางทีข้อมูลดังกล่าวอาจไม่มีประโยชน์อะไร
• ปี 1980: Data Access มีการนำข้อมูลที่จัดเก็บมาสร้างความสัมพันธ์ระหว่างกัน เพื่อนำไป
• ปี 2000 : Data Mining นำข้อมูลจากฐานข้อมูลมาวิเคราะห์และประมวลผล โดยสร้างแบบจำลอง
3. เพื่อจัดการกับข้อมูลในอดีต (Data archeology)
7. เพื่อเก็บเกี่ยวผลประโยชน์ให้ได้มาซึ่งสารสนเทศที่มีประโยชน์
คุณลักษณะและเป้าหมายหลักของ Data Mining คือ ใช้สกลับหรือค้นหา Pattern ของข้อมูลที่ฝังลึกและซ่อนเร้นอยู่ภายในฐานข้อมูลขนาดใหญ่ โดยใช้สถาปัตยกรรม Client-Server (Client/server architecture) ใช้เครื่องมือสมัยใหม่ที่สามารถแสดงผลแบบกราฟฟิก ผู้ใช้สามารถดูข้อมูลแบบเจาะลึก (data drills) และสามารถใช้เครื่องมือในการสอบถามข้อมูลได้อย่างง่ายดาย โดยไม่ต้องอาศัยความชำนาญของ programmer บ่อยครั้งเราอาจค้นพบผลลัพธ์ที่เราไม่คาดหวังมาก่อน เครื่องมือจะทำให้เราใช้งานได้ง่าย ซึ่งเครื่องมือนอกจากจะแสดงผลกราฟิกได้แล้วยังรวม Spreadsheets เอาไว้ด้วย
เป็นกระบวนการในการค้นหาลักษณะแฝงของข้อมูล (Pattern) ที่ซ่อนอยู่ในฐานข้อมูล
2. คัดเลือกข้อมูล (data selection) เป็นการระบุถึงแหล่งข้อมูลที่จะนำมาทำ mining รวมถึงการนำข้อมูลที่ต้องการออกจากฐานข้อมูล เพื่อสร้างกลุ่มข้อมูลสำหรับพิจารณาในเบื้องต้น
3. การกรองข้อมูลและประมวลผล (Data cleaning and preprocessing) ข้อมูลที่เก็บรวมรวมมามีจำนวนมากจะต้องนำมากรอง เพื่อเลือกข้อมูลที่ตรงประเด็น เพราะบางข้อมูลอาจจะไม่เป็นประโยชน์กับเรา ในขั้นตอนนี้เป็นขั้นตอนที่เราจะได้มาซึ่งคุณภาพของข้อมูล ที่จะนำไปวิเคราะห์
4. การแปลงรูปแบบข้อมูล (Data reduction and transformation) ลดรูปและจัดข้อมูลให้อยู่ในรูปแบบ เดียวกัน มีรูปแบบ (Format) ที่เป็นมาตรฐาน และเหมาะสมที่จะนำไปใช้กับ Algorithm และแบบจำลองที่ใช้ทำ Data Mining
5. เลือก Functions ของ data mining เช่น summarization, classification, regression, association และ clustering เป็นต้น
8. ประเมินผล Pattern และนำเสนอองค์ความรู้ ในขั้นตอนนี้จะเป็นการวิเคราะห์ผลลัพธ์ที่ได้ และแปลความหมาย และประเมินผลว่าผลลัพธ์นั้นเหมาะสมหรือตรงวัตถุประสงค์หรือไม่และนำเสนอ
1. องค์ความรู้เกี่ยวกับคุณลักษณะของข้อมูล (Characterization) เช่น รู้ว่าคนที่สามารถเรียนต่อในระดับปริญญาเอกได้จะพิจาณาได้จากคุณลักษณะใด
3. องค์ความรู้เกี่ยวกับความสัมพันธ์ของข้อมูล (Association) เช่น มีความสัมพันธ์ของการซื้อสินค้าพบว่า ถ้าลูกค้าป๊อบคอร์น จะต้องซื้อเป๊บซี่ตามมา
7. องค์ความรู้เกี่ยวกับข้อมูลอื่น ๆ ในงานที่ค้นพบ (Other data mining tasks)
Data Mining เป็นระดับการนำข้อมูลไปใช้ที่สูงกว่า Data Warehouse และ Data Mart นำเอาข้อมูลมาใช้เพื่อการวิเคราะห์ให้เกิดประโยชน์สูงสุด เพื่อช่วยสนับสนุนการตัดสินใจแก่ฝ่ายบริหาร โดยอาศัยกฏเกณฑ์ต่าง ๆ ในการทำงาน
BI (Business Intelligence) คือ ข้อมูลสรุปที่สามารถนำมาช่วยในการตัดสินใจ หรือตอบคำถามในเชิงธุรกิจให้กับผู้บริหารได้ ดังนั้นระบบ BI ที่ดีจะต้องสามารถ นำเสนอข้อมูลสารสนเทศในเชิงภาพรวมของธุรกิจทั้งหมดขององค์กรได้ เพื่อทำให้ขีดความสามารถในการวิเคราะห์ข้อมูลสารสนเทศดี
จากรูป 5.2 จะเห็นว่า Data Mining เป็นส่วนประกอบอันใหม่ ที่มีความสำคัญของ BI(Business Intelligence) อย่างหนึ่ง คุณค่าของข้อมูลที่ใช้สนับสนุนการตัดสินใจจะเพิ่มขึ้นเรื่อย ๆ จากด้านล่างสู่ด้านบนสุดของปิรามิด
4. จากฐานข้อมูลพิเศษหรือที่เก็บข่าวสารพิเศษ ซึ่งได้แก่
– ฐานข้อมูลแบบเก่าในอดีตหรือข้อมูลที่มาจากต่างฐานข้อมูลกัน
ตัวอย่างของการจัดหมวดหมู่ ที่นำมาใช้กับงานด้านธุรกิจ เช่น มีนักวิเคราะห์ขององค์กร
แห่งหนึ่งต้องการรู้เหตุผลว่า “ทำไมถูกค้าบางกลุ่มถึงยังคงซื่อสัตย์จงรักภักดีต่อยี่ห้อสินค้า (Band Loyalty) ขององค์กร และขณะเดียวกันก็มีลูกค้าอีกกลุ่มที่เปลี่ยนใจไปหาคู่แข่ง “ ในการหาคำตอบนี้ นักวิเคราะห์ต้องทำนายลักษณะนิสัยของลูกค้าที่องค์กรอาจต้องเสียไปให้กับคู่แข่ง ดังนั้นเมื่อมีเป้าหมายคือ “อยากทราบเหตุผล” นักวิเคราะห์สามารถนำข้อมูลการซื้อสินค้า ของลูกค้าในอดีตมาทดลองกับแบบจำลองเพื่อวิเคราะห์ผลว่าทำไมลูกค้าบางกลุ่มซื่อสัตย์ บางกลุ่มไม่ซื่อสัตย์
คำตอบที่เราต้องการ (Output) คือรหัสลูกค้า (Cus_type) ถือเป็นตัวแปรตาม(Dependent vairable) ซึ่งผลของตัวแปรตามจะขึ้นอยู่กับตัวแปรอิสระ ((Independent vairable) ในที่นี้คือฟีลด์ Time, Trend และ Status
มีหลายเทคนิคของ Data Mining ที่ใช้ในการแก้ปัญหาแบบ Classification แต่ละเทคนิคก็จะมีหลาย Algorithm ให้เลือกและแต่ละ Algorithm จะให้ผลลัพธ์ที่ต่างกัน ซึ่งปัญหาประเภทนี้จะให้ผลลัพธ์เป็นค่าที่แน่นอน เช่น อาจจะได้คำตอบเป็น (Yes, No) หรือ (High, Medium, Low) เป็นต้น
เทคนิคของ Data Mining ที่ใช้ ในการแก้ปัญหาแบบ Classification ได้แก่
ปัญหาแบบ Regression จะเหมือนกับแบบ Classification ต่างกันตรงที่ผลลัพธ์ที่ได้จาก Regression เป็นค่าแน่นอน ที่ไม่จำกัด จะเป็นค่าอะไรก็ได้ เช่น แบบจำลองทำนายว่า นาย B จะตอบรับข้อเสนอของบริษัท ถ้านาย B ได้รับผลกำไร 1,000 บาท (1,000 เป็นคำตอบเฉพาะที่แน่นอน แต่ไม่จำกัด ซึ่งตัวเลขอาจจะเป็นค่าอื่นไปได้เรื่อย ๆ ต่างจากคำตอบแบบ Yes, No )
เป็นการรวมกลุ่มข้อมูลที่มีลักษณะเหมือนกัน รูปแบบหรือแนวโน้มที่จะเหมือนกัน การใช้เทคนิค Clustering จะไม่มีผลลัพธ์ (Output) ไม่มีตัวแปรอิสระ (Independent Variable) ไม่มีการจัดโครงร่างของวัตถุ เราจะเรียกเทคนิคของ Clustering ว่าเป็นแบบเรียนรู้ข้อมูลโดยไม่ต้องอาศัยครูสอน(Unsupervied Learning) การทำ Clustering จะทำบนพื้นฐานของข้อมูลในอดีต
Ex : องค์กรต้องการทราบความเหมือนที่มีในกลุ่มของลูกค้าของตน เพื่อที่จะให้เข้าใจลักษณะเฉพาะของลูกค้ากลุ่มเป้าหมาย และสร้างกลุ่มของลูกค้าเพื่อที่องค์กรจะได้สามารถขายสินค้าได้ในอนาคต องค์กรจะทำการแยกกลุ่มของข้อมูลลูกค้าออกเป็นกลุ่ม ๆ (หาส่วนที่เป็น Intersection และUnion)
เทคนิคของ Data Mining เพื่อแก้ปัญหาแบบ Clustering คือวิธี Demographic Clustering กับ Neural Clustering
เป็นการประเมินที่ไม่สามารถกำหนดค่าหรือคุณสมบัติที่ชัดเจนได้ ใช้จัดการกับค่าที่มีผล
แบบต่อเนื่อง เช่น ใช้ประเมินรายได้ของครอบครัว ประเมินความสูงของบุคคลในครอบครัว ประเมินจำนวนเด็ก ๆ ในครอบครัว
จะเหมือนกับ Classification และ Estimation ต่างกันตรงที่ Record ถูกแยกจัดลำดับในการ
ทำนายค่าในอนาคต และนำข้อมูลในอดีตมาสร้างเป็นแบบจำลอง ใช้ทำนายสิ่งที่จะเกิดขึ้นในอนาคต เช่น การทำนายว่าลูกค้ากลุ่มใด ที่องค์กรจะสูญเสียไปในอีก 6 เดีอนข้างหน้า หรือ การทำนายยอดซื้อของลูกค้าจะเป็นเท่าใด ถ้าบริษัทลดราคาสินค้าลง 10%
เป็นการหาคำอธิบายถึงสิ่งที่จะเกิดขึ้น โดยอาศัยข้อมูลจากฐานข้อมูล เช่น กลุ่มคนที่มี
เป็นการนำเสนอข้อมูลในรูปแบบกราฟฟิก หรืออาจนำเสนอในแบบ 2 มิติ สร้างรายละเอียด
ในการนำเสนอให้เข้าใจมากยิ่งขึ้น เช่น องค์กรต้องการหาสถานที่ในขยายสาขาใหม่ที่อยู่ในเขตพื้นที่ภาคเหนือของประเทศ ดังนั้นองค์กรจึงใช้แผนที่ Plot ที่ตั้งขององค์กรคู่แข่งที่มีสาขาอยู่ในเขตนั้น เพื่อพิจารณาสถานที่ตั้งที่เหมาะสมที่สุด
1. Neural Network เป็นแนวคิดให้คอมพิวเตอร์ทำงานสมองของมนุษย์ เปลี่ยนตัวเองจากการประมวลผลตามลำดับ (Sequential Processing) ให้เป็นการประมวลผลแบบคู่ขนานได้ (Parallel Processing) มีลักษณะการทำงานโดยแต่ Process จะรับ Input เข้าไปคำนวณ และสร้าง Output ออกมาในลักษณะที่ไม่ใช่การทำงานแบบเชิงเส้นตรง เพราะ Input แต่ละตัวจะถูกให้ลำดับความสำคัญของค่าไม่เท่ากัน ค่าของ Output ที่ได้จากการเชื่อมโยงกันนี้ จะถูกนำมาเปรียบเทียบกับ Output ที่ได้ตั้งเอาไว้ ถ้าค่าที่ออกมาเกิดความคลาดเคลื่อน ก็จะนำไปสู่การปรับค่าหรือน้ำหนัก (weight) ของค่าที่ใส่ไว้ให้แต่ละ Input
Neural Network เป็นการสร้างแบบจำลอง ที่เลียนแบบการทำงานของสมองมนุษย์ มีโครงสร้างเป็นกลุ่มของ Node ที่เชื่อมโยงถึงกันในแต่ละ Layer คือ Input layer, Hidden layer, output layer
โครงสร้างต้นไม้(Decision Trees) ซึ่ง Decision Trees จะมีการทำงานแบบ Supervised Learning (คือการเรียนรู้แบบมีครูสอน) สามารถสร้างแบบจำลองการจัดหมวดหมู่ได้จากกลุ่มตัวอย่างข้อมูลที่กำหนดไว้ก่อนล่วงหน้า เรียกว่า Training set ได้อัตโนมัติ และพยากรกลุ่มของรายการที่ยังไม่เคยนำมาจัดหมวดหมู่ ได้ด้วยรูปแบบของ Tree โครงสร้างประกอบด้วย Root Node, Child และ Leaf Node
มนุษย์ ซึ่งอาศัยการสังเกตที่เกิดขึ้น แล้วสร้างรูปแบบของสิ่งนั้นขึ้นมา เราใช้ MBR เพื่อวิเคราะห์ฐานข้อมูลที่มีอยู่ และกำหนดลักษณะพิเศษของข้อมูลที่อยู่ในนั้น ซึ่งข้อมูลจะต้องมีลักษณะที่สมบูรณ์ การสังเกตจึงจะสมบูรณ์และทำนายผลได้แม่นยำยิ่งขึ้น แบบจำลองจะถูกบอกคำตอบที่ถูกต้อง มีการเก็บคำตอบสำหรับแก้ปัญหาไว้ก่อนล่วงหน้าแล้ว (Supervised Learning)
4. Cluster Detection คือจะแบ่งฐานข้อมูลออกเป็นส่วน ๆ เรียกว่า Segment (กลุ่ม Record ที่มีลักษณะคล้ายกัน) ส่วน Record ที่ต่างกันก็จะอยู่นอก Segment, Cluster Detection ถูกใช้เพื่อค้นหากลุ่มย่อย (Sub Group) ที่เหมือน ๆ กันในฐานข้อมูล เพื่อที่จะเพิ่มความถูกต้องในการวิเคราะห์ และสามารถมุ่งไปยังกลุ่มเป้าหมายได้ถูกต้อง
5. Link Analysis มุ่งเน้นทำงานบน Record ที่มีความสัมพันธ์กัน หรือเรียกว่า Association เทคนิคนี้จะมุ่งไปที่รูปแบบการซื้อหรือเหตุการณ์ที่เกิดขึ้นเป็นลำดับ มีอยู่ 3 เทคนิค คือ
5.1 Association Discovery ใช้วิเคราะห์การซื้อขายสินค้าในรายการเดียวกัน ศึกษาความสัมพันธ์อย่างใกล้ชิดที่ถูกปิดซ่อนอยู่ของสินค้า ซึ่งสินค้าเหล่านั้นอาจมีแนวโน้มที่จะถูกซื้อควบคู่กันไป การวิเคราะห์แบบนี้เรียกว่า Market Basket Analysis คือ รายการทั้งหมดที่ลูกค้าซื้อต่อครั้งที่ Super market การวิเคราะห์นี้สามารถนำมาใช้ประโยชน์ในการตัดสินใจ เช่น การเตรียมสินค้าคงเหลือ การวางแผนจัดชั้นวางสินค้า การทำ Mailing list สำหรับ Direct Mail การวางแผนเพื่อจัด Promotion สนับสนุนการขาย ตัวอย่างของ Association เช่น 75% ของผู้ซื้อน้ำอัดลมจะซื้อข้าวโพดคั่วด้วย
5.2 Sequential Pattern Discovery ถูกใช้ระบุความเกี่ยวเนื่องกันของการซื้อสินค้าของลูกค้า มีจุดหมายที่จะเข้าใจพฤติกรรมการซื้อสินค้าของลูกค้าในลักษณะ logn term เช่น ผู้ขายอาจพบว่าลูกค้าที่ซื้อ TV มีแนวโน้มที่จะซื้อ VDO ในเวลาต่อมา
5.3 Similar Time Sequence Discovery ค้นหาความเกี่ยวเนื่องกันระหว่างข้อมูล 2 กลุ่ม ซึ่งขึ้นต่อกันทางด้านเวลา โดยมีรูปแบบการเคลื่อนที่เหมือนกัน ผู้ขายสินค้ามักใช้เพื่อดูแนวโน้มเพื่อเตรียม Stock เช่น เมื่อไรก็ตามที่ยอดขายสินค้าน้ำอัดลมสูงขึ้น ยอดขายมันฝรั่งจะสูงขึ้นตาม
6. Genetic Algorithm (GA) เปรียบเสมือนเป็นการสร้างพันธุกรรมที่ดีสุด บนขั้นตอนของวิวัฒนาการทางชีวภาพ แนวคิดหลักคือ เมื่อเวลาผ่านไป วิวัฒนาการของเซลล์ชีวิตจะเลือกสายพันธุ์ที่ดีที่สุด “Fittest Species” GA มีความสามารถในการทำงานแบบรวมกลุ่มเข้าด้วยกัน เช่น มีการแบ่งกลุ่มและจัดรวมกลุ่มข้อมูลเป็น 3 ชุด ขั้นตอนการทำงานของ GA เริ่มจาก
– จับกลุ่มข้อมูลเป็นกลุ่ม ๆ ด้วยการสุ่มเดา เปรียบเหมือนกลุ่ม 3 กลุ่มนี้เป็นเซลล์ของสิ่งมีชีวิต GA จะมี Fittest Function ที่จะบอกว่ากลุ่มข้อมูลใดเหมาะกับกลุ่ม ๆ ใด โดย Fittest Function จะเป็นตัวบ่งชี้ว่าข้อมูลเหมาะกับกลุ่มมากกว่าข้อมูลอื่น ๆ
– GA จะมี Operator ซึ่งยอมให้มีการเลียนแบบและแก้ไขลักษณะของกลุ่มข้อมูล Operator จะจำลองหน้าที่ของชีวิตที่ถูกพบในธรรมชาติ คือ มีการแพร่พันธุ์ จับคู่ผสมพันธ์ และเปลี่ยนรูปร่างตามต้นแบบของพันธุกรรม เปรียบกับข้อมูลถ้ามีข้อมูลใดในกลุ่มถูกพบว่าตรงกับคุณสมับัติของ Fittest function แล้ว มันจะคงอยู่และถูกถ่ายเข้าไปในกลุ่มนั้น แต่ถ้าไม่ตรงกับคุณสมบัติ ก็ยังมีโอกาสที่จะถ่ายข้ามไปยังกลุ่มอื่นได้
7. Rule Induction ดึงเอาชุดกฎเกณฑ์ต่าง ๆ มาสร้างเป็นเงื่อนไขหรือกรณี วิธีการของ Rule Induction จะสร้างชุดของกฎที่เป็นอิสระ ซึ่งไม่จำเป็นต้องอยู่ในรูปแบบของโครงสร้างต้นไม้
8. K-nearest neighbor (K-NN) จะใช้วิธีในการจัดแบ่งคลาส โดยจะตัดสินใจว่าคลาสไหนที่จะแทนเงื่อนไขหรือกรณีใหม่ ๆ ได้บ้าง โดยการตรวจสอบจำนวนบางจำนวนของกรณีหรือเงื่อนไขที่เหมือนกันหรือใกล้เคียงกันมากที่สุด โดยจะหาผลรวม (Count Up) ของจำนวนเงื่อนไข หรือกรณีต่าง ๆ สำหรับแต่ละคลาส และกำหนดเงื่อนไขใหม่ ๆ ให้คลาสที่เหมือนกันกับคลาสที่ใกล้เคียงกับมันมากที่สุด
K-NN ค่อนข้างใช้ปริมาณงานในการคำนวณสูงมากบนคอมพิวเตอร์ เพราะเวลาสำหรับการคำนวณจะเพิ่มขึ้นแบบแฟคทอเรียล ตามจำนวนจุดทั้งหมด เทคนิคของ K-NN จะมีการคำนวณเกิดขึ้นทุกครั้งที่มีกรณีใหม่ ๆ เกิดขึ้น ดังนั้นถ้าจะให้เทคนิคแบบ K-NN ทำงานได้เร็ว ข้อมูลที่ใช้บ่อยควรเก็บอยู่ใน MBR (Memory-Based Reasoning)
– Association ใช้หากฎความสัมพันธ์ที่เกิดขึ้นระหว่างกลุ่มของข้อมูล (Item) ต่าง ๆ ใช้ใน
– Sequence Detection เหมือนกับ Association แต่จะนำเหตุการณ์ที่เกิดขึ้น และเพิ่มตัวแปร
ด้านเวลาเข้ามาเกี่ยวข้องด้วย เพื่อใช้วิเคราะห์พฤติกรรมของข้อมูล
A เป็นเหตุการณ์ที่เกิดขึ้นก่อน (Antecedent) หรือ LHS (Left-Hand Side)
เช่น ในกฎของความสัมพันธ์ “ถ้าซื้อค้อน แล้วจะซื้อตะปู “ เหตุการณ์ที่เกิดขึ้นก่อนคือ ค้อน เกิดหลังคือ ตะปู
10. Logic Regression เป็นการวิเคราะห์ความถดถอยแบบเส้นตรงทั่วๆ ไป ใช้ในการพยากรณ์ผลลัพธ์ของ 2 ตัวแปร เช่น Yes/No , 0/1 แต่เนื่องจากตัวแปรตาม (Dependent Variable) มีค่าเพียง 2 อย่างเท่านั้น จึงไม่สามารถสร้างแบบจำลอง (Model) ได้สำหรับการวิเคราะห์แบบ Logic Regression
ดังนั้นแทนที่จะทำการพยากรณ์โดยอาศัยเพียงค่าของตัวแปรตามที่ได้ เราจะสร้าง Model โดยอาศัย Algorithm ของความน่าจะเป็นของการเกิดเหตุการณ์ เราเรียก Algorithm นี้ว่า Log Odds หรือ Logic Transtromation
11. Discriminant Analysis : เป็นวิธีการทางคณิตศาสตร์ที่เก่าแก่วิธีหนึ่งซึ่งใช้ในการจำแนก และวิเคราะห์ วิธีนี้ได้รับการเผยแพร่ครั้งแรกในปี 1936 โดย R.A Fisher เพื่อแยกต้น Iris ออกเป็น 3 พันธุ์ วิธีการนี้ทำให้ค้นพบต้นไม้ประเภทอื่น ๆ อีกมาก ผลลัพธ์ที่ได้จากแบบจำลองชนิดนี้ง่ายต่อการทำความเข้าใจ เพราะผู้ใช้งานทั่ว ๆ ไปก็สามารถพิจาณาได้ว่าผลลัพธ์จะอยู่ทางด้านใดของเส้นทางในแบบจำลอง การเรียนรู้สามารถทำได้ง่าย วิธีการที่ใช้มีความไวต่อรูปแบบของข้อมูล วิธีนี้ถูกนำมาใช้มาในทางการแพทย์ สังคมวิทยา และชีววิทยา แต่ไม่เป็นที่นิยมในการทำ Data Mining
12. Generalized Additive Models (GAM) : พัฒนามาจาก Linear Regression และ Logistic Regression มีการตั้งสมมติฐานว่า Model สามารถเขียนออกมาได้ในรูปของผลรวมของ Possibly Non-Linear Function GAM สามารถใช้ได้กับปัญหาแบบ Regression และ Classification
GAM จะใช้ความสามารถของคอมพิวเตอร์ในการค้นหารูปแบบอง Function ที่ให้ Curve ที่เหมาะสม ทำการรวมค่าความสัมพันธ์ต่าง ๆ เข้าด้วยกัน แทนที่จะใช้ Parameter จำนวนมาก เหมือนที่ Neural Network ใช้ แต่ GAM จะก้าวไปเหนือกว่านั้นอีกขั้นหนึ่ง GAM จะประเมินค่าของ Output ในแต่ละ Input เช่นเดียวกับ Neural Network GAM จะสร้างเส้นโค้งขึ้นมาอย่างอัตโนมัติ โดยอาศัยข้อมูลที่มีอยู่
13. Multivariate Adaptive Regression Splits (MARS) : ถูกคิดค้นเมื่อกลางทศวรรษที่ 80 โดย Jerome H. Friedman หนึ่งในผู้คิดค้น CART MARS สามารถที่จะค้นหาและแสดงรายการตัวแปรอิสระที่มีความสำคัญสูงสุดเช่นเดียวกับปฏิสัมพันธ์ระหว่างตัวแปรอิสระ และ MARS สามารถ Plot จุดแสดงความเป็นอิสระของแต่ละตัวแปรอิสระ ออกมาได้ ผลลัพธ์ที่ได้ก็คือ Non-Linear Step-wise regression tools
สามารถนำเทคนิคของ Data Mining ไปวิเคราะห์ข้อมูลในฐานข้อมูล เพื่อนำข้อมูลที่ได้ไปใช้ประโยชน์ในงานด้านต่าง ๆ ดังต่อไปนี้
2. งานด้านธนาคารและการเงิน (Banking / Financial Analysis) เช่น ใช้ในการวิเคราะห์การให้สินเชื่อแก่
กลยุทธ์ ทำให้เกิดการได้เปรียบคู่แข่งทางการค้าในการหาลักษณะการซื้อของลูกค้า ความสัมพันธ์ของการซื้อกับช่วงเวลา ความสัมพันธ์ระหว่างตัวสินค้า และการวิเคราะห์ประสิทธิภาพของการโฆษณา เป็นต้น ช่วยให้สามารถหาวิธีการตอบสนองความต้องการของลูกค้าได้มากที่สุด และอาจหมายถึงส่วนแบ่งทางการตลาดที่เพิ่มขึ้นนั่นเอง
วิธีการเพื่อสร้างความเชื่อมั่นในเรื่องความปลอดภัยของข้อมูล ในขณะที่มีการพัฒนาวิธีการเข้าถึงข้อมูล การและ Mining ให้สะดวกต่อการใช้งานมากขึ้น
การจัดเรียงตัวของหน่วยพันธุกรรม เพื่อหาสาเหตุความผิดปกติที่ทำให้เกิดโรค รวมไปถึงด้านการวินิจฉัยโรค การป้องกัน และการรักษา
และ software, หน่วยงานรัฐบาลและกระทรวงกลาโหม (Government and defense), สายการบิน (Airlines), งานด้านสุขภาพ (Health care), งานด้านการข่าว (Broadcasting) และงานด้านกฎหมาย (Law enforcement) ได้อีกด้วย
ใช้ Intelligent Data Mining เพื่อการค้นพบข้อมูลและข่าวสารภายในคลังข้อมูล (Data warehouses) ที่ซึ่งการสอบถามและการออกรายงาน (Reports) นั้นจะไม่แสดงผลออกมา เช่น การค้นหา Patterns ในข้อมูลและลงความเห็นตามกฎ ที่เราได้กำหนดไว้ การใช้ Patterns และ Rules ในการแนะแนวทางการตัดสินใจและ
รูปที่ 5.6 ขั้นตอนการเก็บรวบรวมข้อมูลเพื่อประมวลผลใน Data Mining
สามารถใช้เครื่องมือหรือเทคนิคต่อไปนี้ในการขุดค้นข้อมูลใน Intelligent data mining
5.14.1 Association Rule ใช้ในการหากฎความสัมพันธ์ซึ่งกันและกัน ของสินค้า 2 ประเภท โดยคำนวณหาค่าสนับสนุน (support) และค่าความน่าเชื่อมั่น (Confidence) ดังนี้
Data Mining คืออะไร ทำไมจึงเป็นสิ่งที่องค์กรธุรกิจระดับโลกต้องจับตา
มีคำหนึ่งที่เกิดขึ้นมาพร้อมกับคำว่า Big data ก็คือ Data Analytics ซึ่งนั่นก็คือ การวิเคราะห์ข้อมูล หากเปรียบไปแล้ว Big data ก็เป็นเพียงก้อนข้อมูลขนาดใหญ่มหึมาเท่านั้น และมันจะไม่มีค่าเลยหากเราไม่สามารถแกะหรือถอดมันออกมาวิเคราะห์ได้ ในส่วนของการวิเคราะห์หรือ Data Analytics สามารถทำได้หลากหลายวิธีและหลายรูปแบบ แต่หนึ่งในนั้นและเป็นวิธีที่องค์กรธุรกิจระดับโลกหลายแห่งเลือกใช้ก็คือ Data Mining ซึ่ง Data Mining คือการวิเคราะห์แยกแยะและหาความสัมพันธ์ของข้อมูลที่อยู่ใน Big data เสมือนเป็นการทะลวงหรือขุดเข้าไปในก้อนข้อมูลนั้น แล้วจับข้อมูลเหล่านั้นมาแยกหาความสัมพันธ์ของข้อมูลแต่ละชุดแต่ละแบบ เปรียบไปก็เหมือนเราทำเหมืองพลอย เมื่อขุดหาพลอย เราก็จะได้พลอยออกมาหลายชนิด ซึ่งแต่ละชนิดก็จะต้องมีการแยกประเภทที่เหมือนและต่างกันไว้ สำหรับข้อมูลก็เป็นเช่นนั้นเหมือนกัน ต้องมาการจำแนกและตีความว่าเป็นข้อมูลอะไร เป็นตัวเลข เป็นตัวอักษร แต่ละชุดข้อมูลมีความเกี่ยวโยงกันอย่างไร เมื่อแยกประเภทตามความสัมพันธ์ได้แล้ว ก็จะช่วยทำให้เราสามารถนำข้อมูลเหล่านี้มาใช้ได้โดยง่ายมากขึ้นนั่นเอง

ตอนนี้ไปไหนทำอะไรที่เกี่ยวข้องกับธุรกิจการงาน ทั้งอุตสาหกรรมและเทคโนโลยี เราจะหนีไม่พ้นคำว่า Big data เราต่างรู้ว่า Big data สำคัญอย่างไร แต่น้อยคนนักจะรู้ว่าจะหาประโยชน์หรือนำ Big data มาใช้ประโยชน์ได้อย่างไร data mining คือสิ่งนั้น เป็นทางเลือกที่จะช่วยให้คุณใช้ประโยชน์จาก Big data ได้จริง เรื่องนี้จึงเป็นเรื่องที่ผู้นำองค์กรยุคใหม่ควรจะต้องตระหนักและใส่ใจ หลายคนอาจจะยังมองภาพไม่ออกว่า ประโยชน์จริง ๆ ของ Data Mining คืออะไร มันเอามาใช้ให้เห็นภาพจริง ๆ ได้อย่างไร เราก็ขอยกตัวอย่างเกี่ยวกับวงการแพทย์ ที่ได้มีการทำ Data Mining ไปใช้ อย่างที่ทราบกันว่าปัจจุบันมีคนป่วยด้วยโรคต่าง ๆ มากขึ้น เชื้อไวรัสใหม่ ๆ ก็เกิดขึ้นเรื่อย ๆ ในวงการแพทย์มีการเก็บสถิติข้อมูลเกี่ยวกับผู้ป่วยด้วยโรคต่าง ๆ จากการติดเชื้อไวรัสไว้มากมาย ซึ่งข้อมูลนี้เชื่อมโยงถึงกันทั่วโลก แต่ในภูมิภาคอาเซียนและในประเทศไทย เชื้อไวรัสบางชนิดอาจไม่มีการแพร่ระบาด และความชุกของโรคอาจกระจุกตัวอยู่แค่เพียงภาคไหนสักแห่งของประเทศไทยเท่านั้น ในลักษณะนี้ข้อมูลผู้ป่วยด้วยเชื้อไวรัสจากทั่วโลกก็คือ Big data และการเจาะเข้าไปในจำนวนข้อมูลเหล่านี้เพื่อเอาข้อมูลของผู้ป่วยในภูมิภาคอาเซียนและในประเทศไทยออกมาจำแนก ว่าความชุกและการแพร่ระบาดของเชื้อเยอะที่ภาคไหน ผู้ป่วยส่วนใหญ่เป็นชายหรือหญิงและมีอายุเท่าไหร่ เหล่านี้ก็คือ Data Mining นั่นเอง ซึ่งเมื่อแพทย์ได้ข้อมูลที่ชัดเจนแบบนี้แล้ว ก็จะเฝ้าระวัง ประกาศเตือนประชาชน รวมถึงจัดหายาและวัคซีนได้ทันนั่นเอง
เรื่องของวิธีการวิเคราะห์และหาความเชื่อมโยงของข้อมูลหรือ Data Mining คือสิ่งที่ต้องจับตามองและให้ความสนใจกันจริง ๆ เพราะนี่คือสิ่งที่จะทำให้พวกเราได้ประโยชน์อีกมากมายจากข้อมูลที่มีอยู่มากมาย และนับเป็นโอกาสและช่องทางของการเติบโตของภาคธุรกิจด้วย